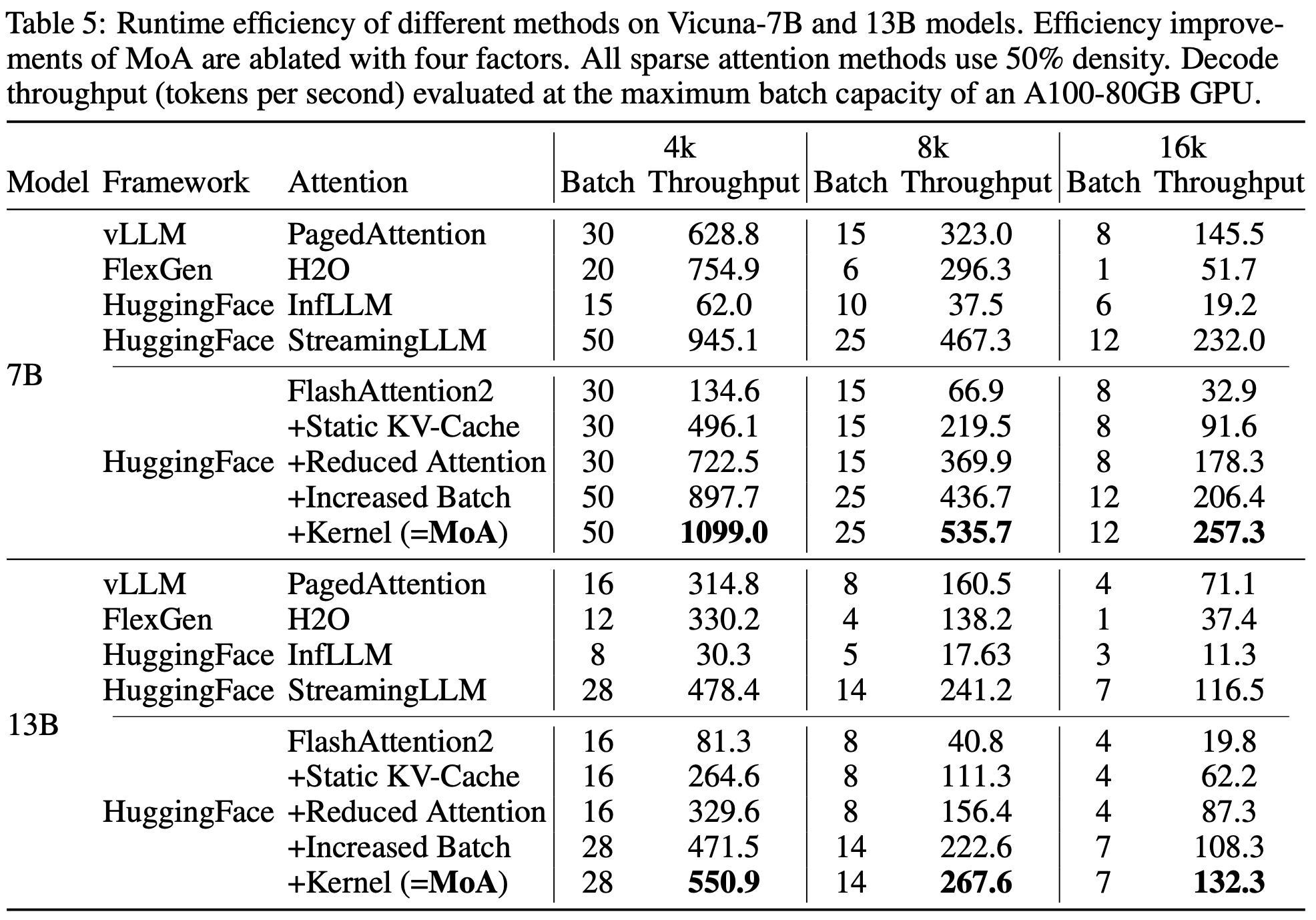
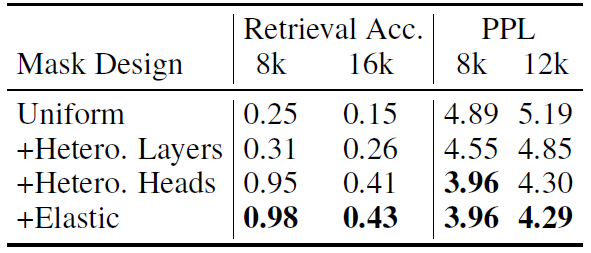
Overview
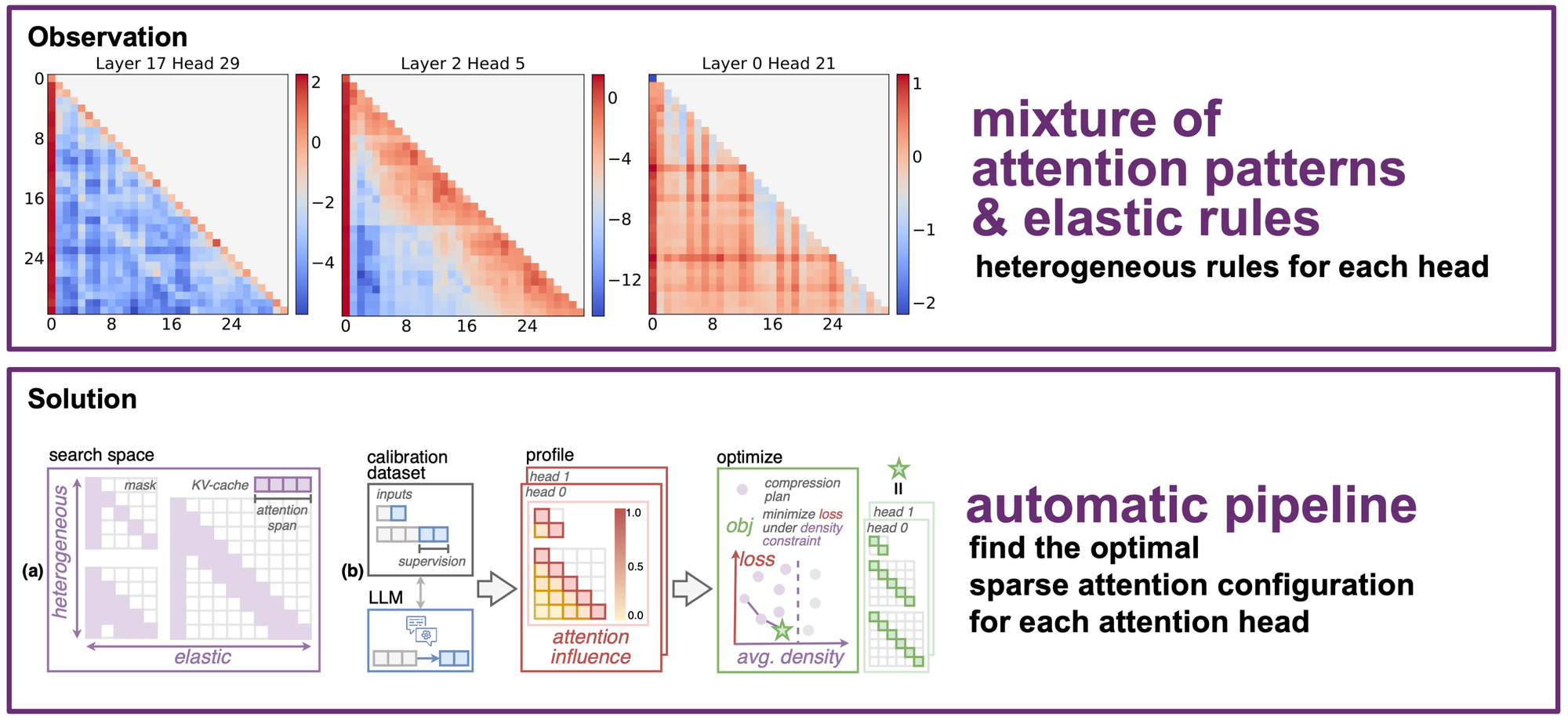
Short attention spans can still preserve long-context behavior.
Uniform sliding windows give every head the same local budget. MoA assigns each head its own elastic span rule so local heads stay cheap and global heads keep enough context.
Uniform spans misallocate budget. Some heads mainly need local context, while others require broad context to preserve retrieval and understanding.
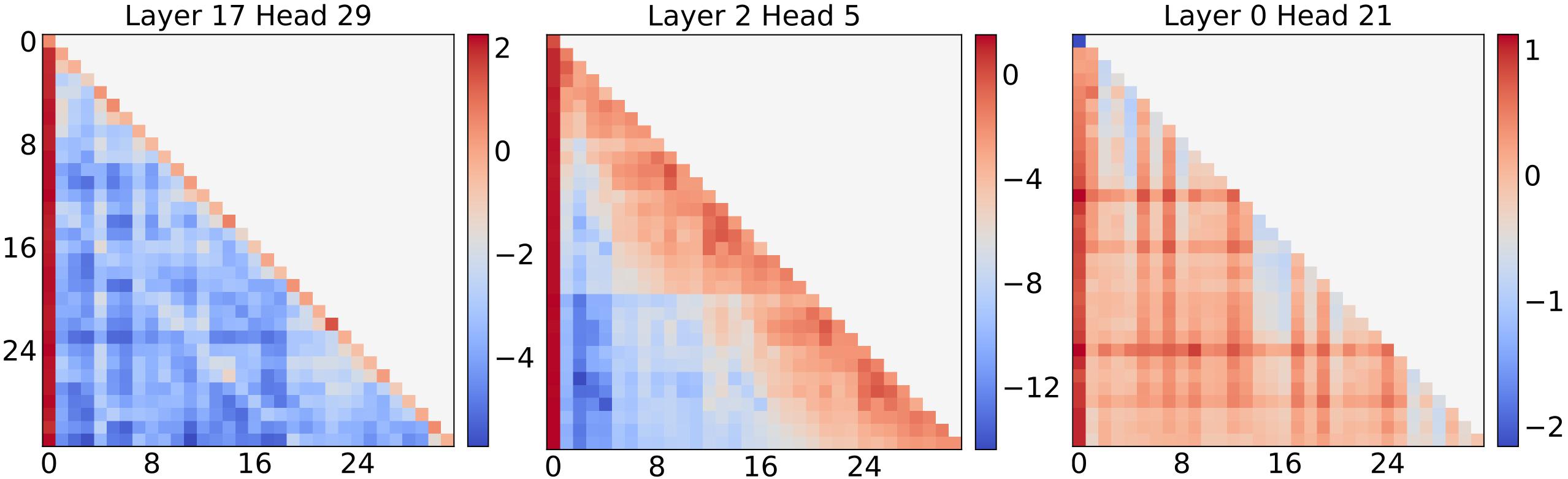
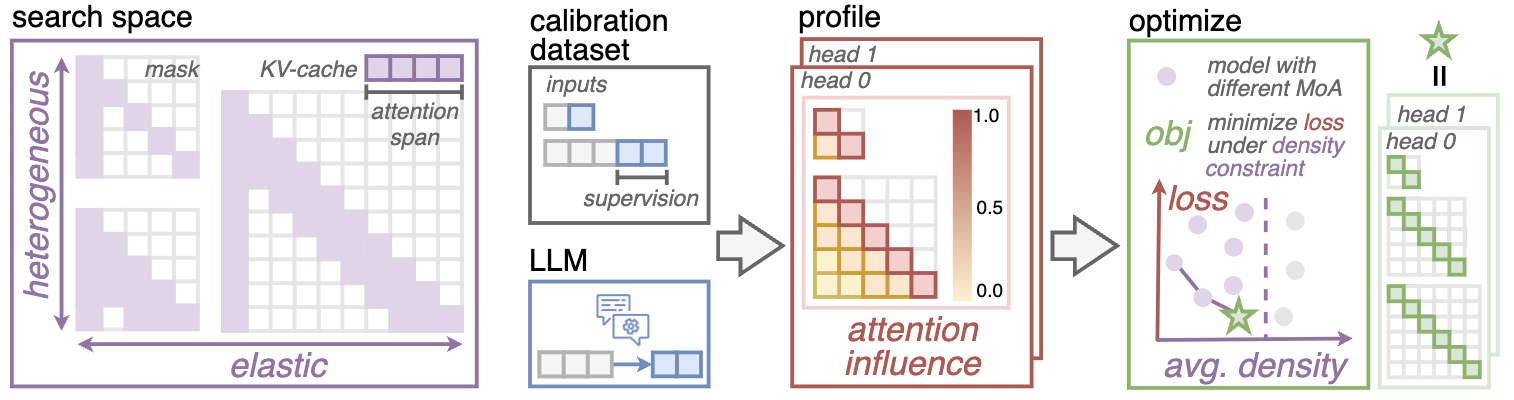
MoA searches per-head elastic rules. Attention span becomes a head-specific function of input length under a target density constraint.
The method is training-free. A calibration pass profiles attention influence, then an optimizer selects the best heterogeneous span plan.